
In the previous articles, we have described what the Oracle Problem is and what parts of this problem are already solved. Today we’d like to shed some light on data aggregation, which is one of the main ways for improving the quality of oracle services. Data aggregation is a process of collecting different values (usually from different sources) and summarizing them (usually to a single value). A simple example is collecting price data for ETH/USD pair from several exchanges and calculating the average value. But why is it so important and how can a correctly picked aggregation method protect your DeFi protocol from being hacked? Scroll down to learn more ⬇️
Why data aggregation
The quality of data delivered by an oracle service depends on two main criteria:
- Data availability — which means that the oracle data should be always available for end users (or smart contracts) and should be updated with the promised frequency
- Data correctness — it may be defined in different ways and usually depends on the type of data. E.g. correctness of objective data (like results of the given football match) can be easily verified, but with less-objective data (like ETH token price denominated in USD) it can be way more difficult to define correctness
Data aggregation improves the quality of the oracle data and helps oracles meet the requirements in many ways. First of all, aggregating data from different sources increases the value correctness, because even if some small subset of sources eventually corrupts it should not corrupt the aggregated value. Besides that, the aggregated value usually represents a “more fair” or “more correct” value. Additionally, aggregation improves data availability, because even if some sources stop working — the oracle service will still be able to function properly.
As we mentioned in the previous articles, the main product-market fit for oracles today is the provision of pricing data, which is very useful for creating synthetic and derivative assets, insurance, lending, and many other protocols. That’s why this article is mainly focused on the methods of aggregating price values.
Average price value
The first aggregation algorithm that comes to mind is calculating the mean value. It is very simple and may look quite “fair”but it actually has a significant disadvantage, because it is not resistant to manipulation by even a small subset of corrupted sources. For example, assume that you want to get the ETH/USD value from 5 different exchanges, where 4 of them claim that the current price is around $2000, but one of them insists that it’s only $1. Then the average value is ~$1600, which is too deviated and can not be considered correct. That’s why usually mean value calculation, as well as other aggregation methods, are combined with an Interquartile Range Filter, which helps to filter out outliers and market manipulations.
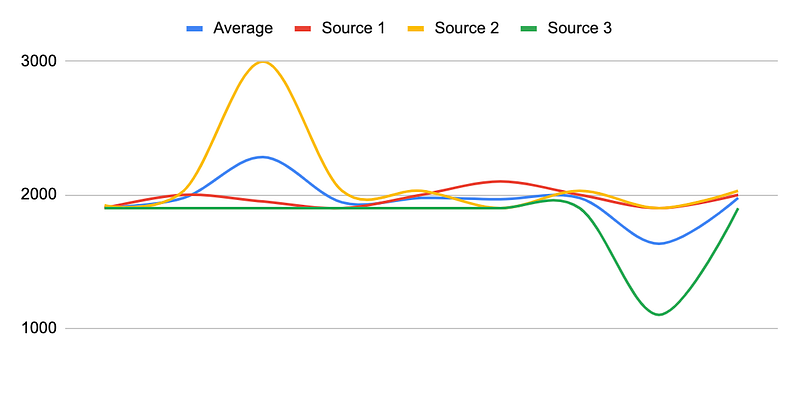
Median price value
There is another approach, which uses a median value calculation. It’s way better than the average value and definitely more resistant to manipulations by corrupted sources. However, even this method cannot be considered a perfect way to calculate price value. As an example, assume that you take the same ETH/USD value from one large crypto exchange ($100m daily trading volume on ETH/USD market) and 4 small ones (~$10k daily trading volume on ETH/USD market), and the large exchange provides value $2000, but all the small ones — less than $1900. Then the aggregated median value, in this case, will be less than $1900, but, as you can guess, it’s not close enough to the “real” market value.

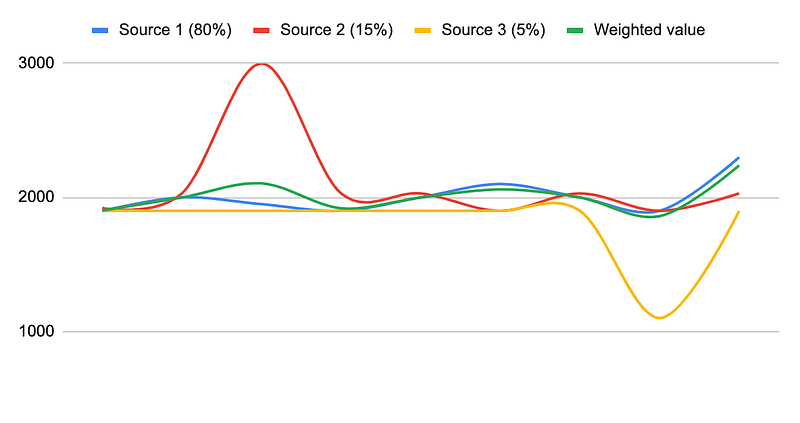
Volume-Weighted Average Price (VWAP)
The next, and one of the best, aggregation method is the volume-weighted average price calculation. As the name suggests, this is a trade-based price determination that takes into account the different volumes of trades in different sources. The more trading volume a source has — the bigger the weight of its price value. Sometimes, VWAP is also combined with the Interquartile Range Filter to filter out outliers (see VWAPIR).
It is worth mentioning, that thanks to the easy liquidity calculation on Decentralized Exchanges (like Uniswap, Sushiswap, PancakeSwap, and others), it is also possible to calculate the Liquidity-Weighted Average Price (LWAP) aggregated from multiple decentralized exchanges, which has similar advantages to the VWAP.
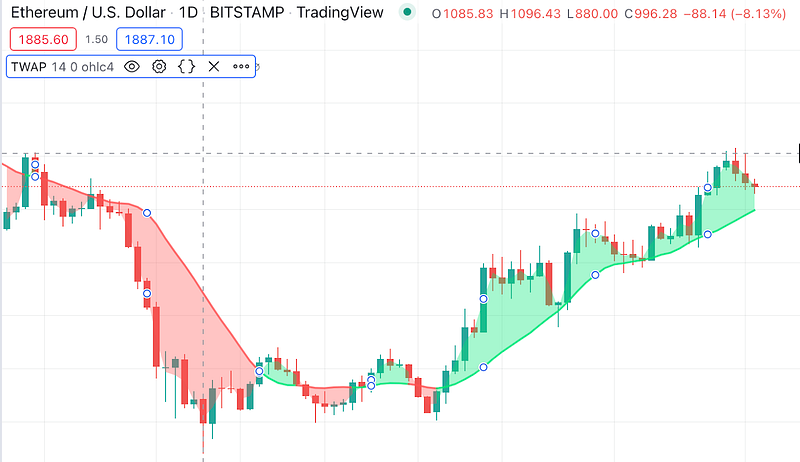
Time-weighted Average Price (TWAP)
Another common method for price aggregation is based on weighted average price, weights of which are defined by the time criterion. This is especially useful for calculating price values based only on decentralized exchanges. Many DEXes even offer their own TWAP-based oracle solutions (example: Uniswap TWAP oracle). But besides DEX-based oracles, this method can be used to make market manipulation harder in case of a limited amount of data sources. We, at RedStone, use TWAPs to make the pricing data of low-liquidity assets more stable and reliable.
So, what method is the best?
The ideal price value actually depends on the requested order (amount, buy/sell type) and it should take into account order books on each available exchange with all related fees. This is quite difficult to calculate. Fortunately, a sufficiently good price value does not need to be ideal by definition. And some combinations of aggregation algorithms described above may work great for the majority of use cases in the DeFi space. Nevertheless, it is very important to understand all potential risks before building a DeFi protocol that relies on pricing data from oracles and select the best aggregation method (or methods) for your case. Feel free to reach out to us, and we’ll be happy to help you with it 😉
At RedStone we are on a mission to build the next generation of oracles. Our solution has an unrivaled ability to exert significant control over any new data listings. Result? The flexibility to follow any emerging market trends, alongside substantial cost savings, allows us to stay at the frontier of a new wave of Decentralised Finance.
Join us on the journey!


